Beyond keys: The rise of semantic and prefix caching for LLMs
Caching is a fundamental concept in system design. At its core, it involves storing frequently accessed data in a temporary, high-speed storage layer that sits between the user and the primary data source, like a database. The goal is simple: improve performance by serving requests from this fast local store, avoiding slower network calls and database operations. When a request for data is made for the first time, it results in a “cache miss,” and the data is fetched from the database and stored in the cache. Subsequent identical requests result in a “cache hit,” where the data is served directly from the cache, leading to significantly faster response times.
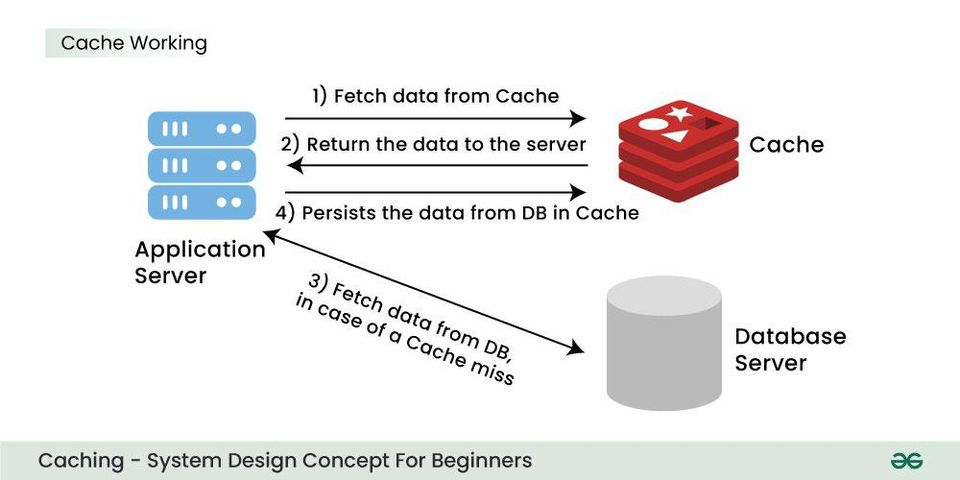
This traditional model, where a cache hit relies on an identical request, works perfectly for predictable queries. However, the game changes with Large Language Models (LLMs). I came across an article from Raul Junco in System Design Classroom that clearly articulates this challenge. He points out that in AI systems, users often ask for the same information using different phrasing. For example:
- “What is semantic caching?”
- “Can you explain how semantic caching works?”
- “Tell me about caching based on meaning.”
All three questions seek the same answer, but to a traditional cache, they are entirely different strings. The result is a cache miss every time, triggering a new, costly call to the LLM for a response you have likely already generated. As Junco’s article puts it:
Caching by key doesn’t work when your users speak in meaning.
This is where new, more intelligent caching methods become essential.
A new approach: Semantic caching with Redis 8
Junco’s article focuses on the new capabilities in Redis 8, which aim to solve this problem at the application/data-layer by understanding the meaning behind a query, not just its literal text. This is achieved through a combination of new features:
- Vector Sets: Redis can now natively store and search vectors. This allows it to find prompts that are “close” in meaning by comparing their vector embeddings, without needing a separate vector database.
- LangCache: This is a managed semantic cache built on Redis. It takes an incoming prompt, creates an embedding, and searches the cache for vectors of previous prompts that are semantically similar. If a close match is found, it returns the cached response, skipping the LLM call entirely.
- Redis Flex: To make storing vast amounts of cached data affordable, Redis Flex uses a hybrid memory model. It keeps “hot” data in RAM for speed and offloads less-used “warm” data to more economical SSD storage.
This approach moves caching from a simple key-match to a more powerful meaning-match, directly addressing the issue of varied user phrasing.
The incumbents’ approach: Prefix caching
While Redis tackles this at the application layer, major AI providers like OpenAI and Anthropic (Claude) have implemented their own form of caching at the API level. Their method is best described as prefix caching.
Instead of understanding semantics, their systems identify and cache the static, initial parts of a prompt. This is particularly effective for applications that repeatedly send large, unchanging blocks of text, such as a detailed system prompt, few-shot examples, or context from a RAG system.
Anthropic (Claude): Provides explicit control via a
cache_controlparameter in the API call. You mark which parts of the prompt are static (e.g., a system message or a large document), and Claude caches them. Subsequent calls only need to process the new, dynamic parts of the prompt, saving on token costs and reducing latency. You can find the details in their prompt caching documentation.OpenAI: Implements this automatically for prompts over 1024 tokens. It hashes the beginning of a prompt and routes requests with the same hash to a server that has that prefix cached. While automatic, it offers less direct control than Claude’s method. More details are in their prompt caching guide.
Comparison: Semantic vs. prefix caching
These two strategies solve related but distinct problems. Semantic caching is user-focused, while prefix caching is developer-focused. Here is a breakdown of the differences:
| Feature | Redis (Semantic Caching) | Claude & OpenAI (Prefix Caching) |
|---|---|---|
| Core Mechanism | Vector similarity search on prompt embeddings. | Exact match of the initial, static part (prefix) of a prompt. |
| Solves For | Varied user phrasing for the same intent. | Repetitive, large static contexts (e.g., system prompts, RAG). |
| Implementation | Application-layer service (e.g., Redis Cloud). | Built directly into the LLM provider’s API. |
| Control | Granular control over similarity thresholds, TTLs, etc. | API-level control (explicit in Claude, automatic in OpenAI). |
| Flexibility | High. Understands meaning, independent of exact wording. | Low. Requires the prefix to be 100% identical. |
| Primary Benefit | Reduces redundant calls from semantically similar user inputs. | Reduces token processing for large, developer-defined contexts. |
Why this matters
The evolution of caching for AI systems is a big step towards making them more efficient, scalable, and affordable. The quote from Junco’s article is a powerful summary:
Every LLM call you make that could’ve been a cache hit is tech debt you’re paying in real time.
Semantic caching, like the solution from Redis, represents a fundamental shift. It addresses the inherent ambiguity of natural language. Prefix caching, on the other hand, is a pragmatic and powerful optimisation for common development patterns like RAG.
They are not mutually exclusive. A truly optimised system will likely use both: prefix caching at the API level to handle static system instructions and document context, and semantic caching at the application level to handle the diversity of user queries. This layered approach seems to be the most logical path forward for building robust and cost-effective AI applications.