Rethinking RAG with visual document analysis
I recently came across an article from the company Morphik that details their approach to Retrieval-Augmented Generation (RAG). Instead of following the ‘regular’ path of parsing documents by extracting text, they treat each page as an image. This method sidesteps many of the common frustrations involved in processing complex documents with tables, charts, and intricate layouts.
The problem with traditional RAG pipelines is their fragility. Extracting text via OCR, detecting layouts, and chunking information intelligently are all steps where context can be lost. Morphik’s team came up with this question:
Why are we deconstructing these documents just to reconstruct meaning? What if we treated them the way humans do: as visual objects?
How it works
Their solution is built upon research like Google’s ColPali. The architecture treats each document page as a high-resolution image. This image is then divided into patches, and a Vision Transformer creates rich embeddings that capture both the textual and visual information in context. A language model then refines these embeddings to understand the overall structure.
When a user submits a query, the system uses a technique called “late interaction” to find relevant patches. It does not just look for keywords; it understands the spatial relationship between elements on the page. For example, it can connect the text “Q3 revenue” with a nearby chart showing an upward trend.
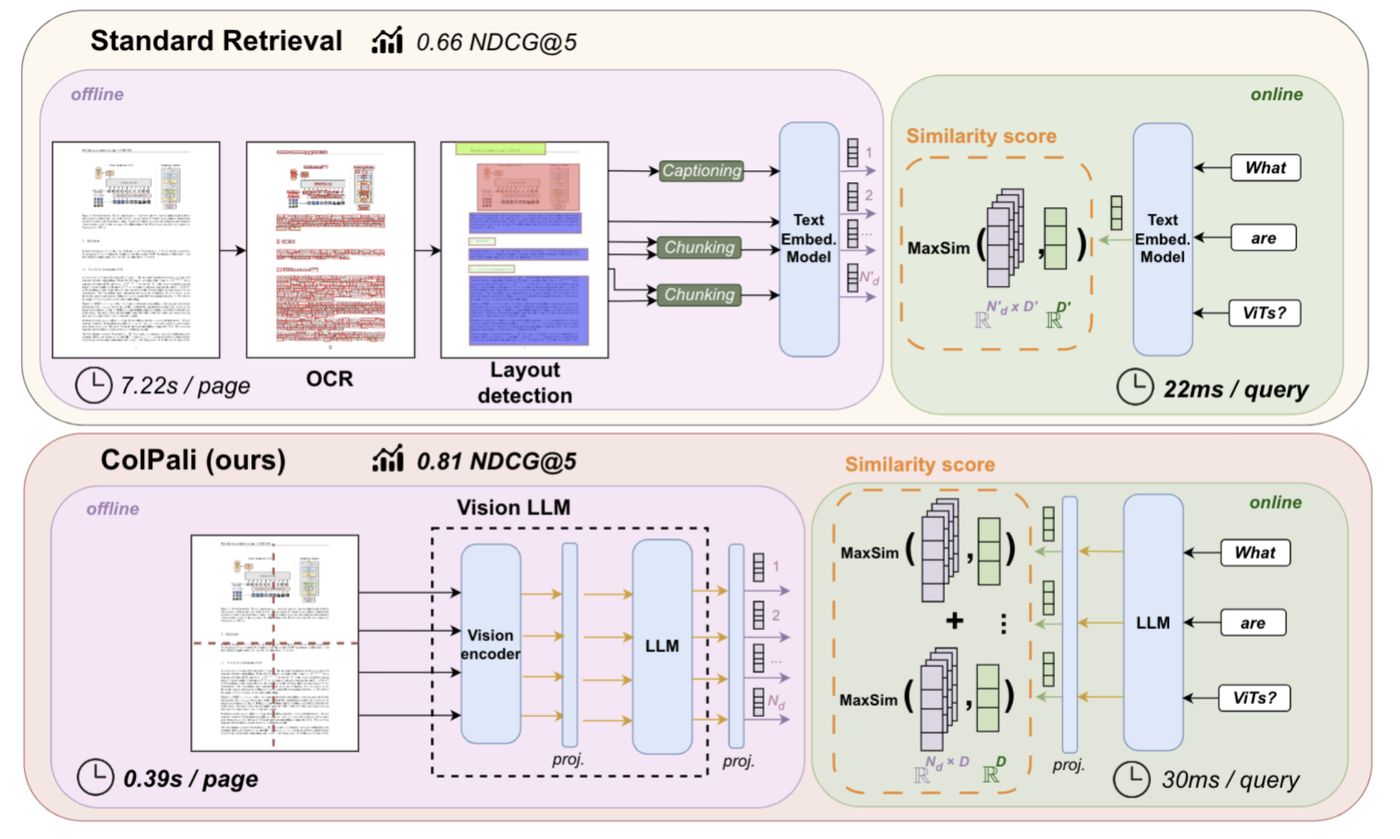
The performance claims are promising. On a challenging financial document benchmark, they report a significant accuracy advantage over other methods.
The results were striking: while other end-to-end providers peaked at around 67% accuracy… Morphik delivered 95.56% accuracy on the same evaluation set.
My thoughts on this approach
This is a innovative way to handle the messiness of real-world documents. For financial reports, technical manuals, and other visually rich materials, preserving the original layout is not just a convenience—it is essential for preserving meaning. This method seems particularly good for use cases where the visual context is as important as the text itself.
However, this approach also presents some interesting trade-offs. While it excels at understanding visual context, it might be less suitable for tasks that depend on the extraction of clean, reusable text. For example, workflows that require copying and pasting specific clauses from a legal document or exporting raw data from a table into a spreadsheet would still benefit from traditional text extraction.
Furthermore, a key consideration for any organisation is how this model handles 100% text-based documents or tasks requiring precise, literal string matching, such as finding a specific serial number. The value of this visual-first strategy is highest when the layout itself contains information. For a simple text file, the benefits are less obvious.
Overall, Morphik’s work is a great example of thinking differently to solve a persistent problem. It is a reminder that sometimes the most effective solution is the one that works with the nature of the information, rather than trying to force it into a different format.